%load_ext pretty_jupyter
First Steps in Python and Learning Outcomes¶
This walkthrough is part of the ECLR page.
Here we assume that you have installed Python on your computer (see the Python Installation walkthrough).
In this walkthrough, we’ll start with the basics of programming and in particular the basics of a good workflow. From there, we’ll discuss how to manage data, perform calculations. By the end of this section, you’ll have the foundation to explore advanced topics and unlock Python’s full potential—whether in data science, econometrics, or creating the next big app or website.
This document allows you to experience fundamental functionality using Python and Jupyter Notebook. In particular, this is for you:
- write your first Python code!
- to explore basic syntax by understanding Python's fundamental data types: integers, floats, strings, and booleans and using the built-in Python functions like
print()to display outputs andtype()to inspect data types. - to learn how to import libraries such as
numpyandpandasto start working with arrays and tabular data and install additional libraries directly from Jupyter Notebook using!pip install. - to recognise and fix common Python errors, such as
SyntaxErrorandNameError. - to learn about about data types
- to undertake some basic data manipulation
- to develop a roadmap to explore advanced Python topics such as implementing visualisation techniques with
matplotlibandseabornand advanced econometric modelling withstatsmodelsorscikit-learn.
We recommend that you have installed VS Code as your IDE.
Prepare your Workspace¶
Before you start, you should create a space (i.e. a folder) on your computer from where you are planning to store all your Python files and data. Ensure you know this folder's exact location and its full path. This will help you navigate to it easily from within Jupyter Notebook.
For instance, if you create a folder named PyWork on your C drive, then the path to your folder will be C:/PyWork.
For this computer lab, we are using the datafile STATS19_GM_AccData.csv. You should download this data file (click on the download icon from that linked page) into the folder you just created and want to work from. The data file in your working folder ensures that Python can easily access it without complex file paths. It is also a good idea to have the Data Dictionary ready. This will help you understand the structure and variables in the data.
Prepare your script file or notebook and libraries¶
A crucial part of working with Python is that you document your work by saving all the code commands you apply in either a script file (.py) or a Jupyter notebook (.ipynb).
We recommend that on most occasions (and certainly at the beginning of your coding career) you should work in Jupyter Notebook with the extension .ipynb. This file allows you to save your commands (code), comments, and outputs in one document. The process that you need to follow consists of the steps outlined here:
- Open VS Code.
- Create a new notebook by going to File → New File and then chose Jupyter Notebook.
- Give that file a sensible name and save it in your working directory (e.g.,
my_first_pywork.ipynb). - Remember to frequently save your work (CTRL + S on windows or Cmd+S on a Mac).
Now, let's create a Jupyter Notebook file following the abovementioned steps. A Jupyter notebook basically consists of code and markdown blocks. markdown blocks, like the one in the image below, basically contain text and code blocks (see below) will contain python code. It is best to start with a markdown block in which you tell yourself what this notebook is about. Whether a block is code or markdown you can see at the bottom right of every block. You can change between the two types if you click the three dots in the top right of each block.
If you want a new block you click on either the + Code or the + Markdown button. A list with useful Jupyter notebook formatting support is available from here.

Let's add a code block in which we check (or set) the working directory Unlike R, Python does not have a setwd() function. Instead, you can use the os module to check and change your working directory. Setting the working directory ensures that Python knows where to look for files and where to save outputs!
import os # Import the os library
print("Current Working Directory:", os.getcwd())
Current Working Directory: c:\Pycode\ECLR\Py_coding
Note: Adding comments to your Python code is essential to avoid staring at it tomorrow, wondering, “What was I even thinking here?” In Python, the computer ignores anything after the # symbol but is treasured by you (or anyone else reading your code). Comments are not for Python; they’re for your sanity!
The os module is part of Python’s standard library, so you don’t need to install anything extra. It allows you to interact with the operating system (e.g., checking the current directory, changing directories, or listing files). The os.getcwd() gets the current working directory and tells you which folder Python currently uses as its default location for reading or saving files. The output will differ for each user. In this example,we have Current Working Directory: C:\Users\Admin.
In your VS Code window this will look as in the image below. If you have a code chunk you can execute the code in the chunk you either click the play button (yellow highlight) or you type CTRL + ENTER. The output of the code will show directly below (green highlight).
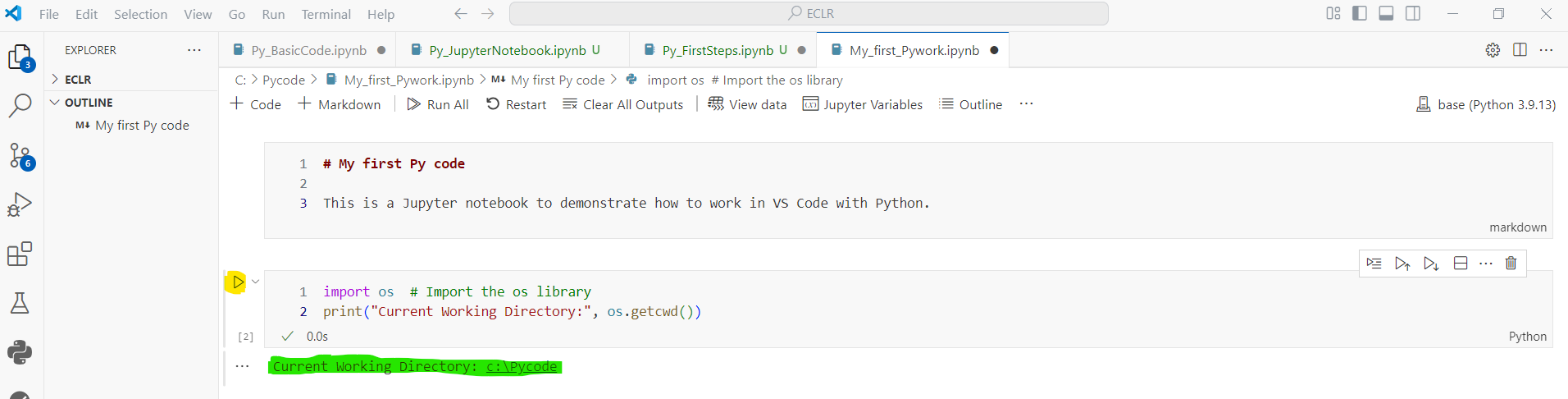
From now onwards we will not show screenshots of a Jupyter notebook anylonger, but only discuss the code which you will copy and paste into a code chunk in your notebook. By the way, this very document has been written as a Jupyter notebook.
If you want to change the working directory, you will have to use the os.chdir() function and in the parentheses () specify the full path of your desired folder. The os.chdir() function changes the current working directory to the specified folder. Note that all backward slashes (\) have to be replaced by forward slashes (/) to avoid escape character issues.
os.chdir("C:/PythonWork") # Replace with your desired path
print("New Working Directory:", os.getcwd())
Python libraries¶
Python libraries provide additional functions that extend Python’s capabilities. You will have to use libraries as lots of the great functionality that gives Python its power comes through libraries. Libraries have to be loaded (or imported in python speak) before every use (typically at the beginning of each script or notebook). However, before you can import them you will have to install them. Installing you only have to do once on your computer.
We start by attempting to load a library that, most likely is not available to you at this stage. It is called pybrain. We only use this here for you to see what would happen if you were trying to load/import a library that has not been installed yet. If you run the following code you should get an error message.
import pybrain as pybrain
Your likely error message will look something like this:
ModuleNotFoundError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_7984\1738476634.py in
-> 1 import pybrain as pybrain
ModuleNotFoundError: No module named 'pybrain'
Essentially python is telling you that the pybrain library is not yet installed on your computer.
Installing libraries¶
This needs doing once on your computer. This is done via the terminal. The terminal is a tool via which you can type instructions to your computer (as opposed to Python). And the installing is done by your computer and not by Python. Let's say we need to install the packages pandas and numpy as we need them later.
Open the terminal by clicking on the Terminal item in the menu and chosing New Terminal. This will open at the bottom of your screen as indicated in this screenshot.

In the terminal you type pip install and then the name of the package you wish to install, here pandas. Then press enter and the computer will do its stuff. When you see the prompt again (here C:\Pycode\ECLR) and there is no error message you are good to go. Repeat that for all the packages needed.
We typically do this via the terminal as we do this only once on the computer and there is no need to save that code and re-use it.
Loading/Importing libraries¶
Let's load the libraries that we want to use, assuming that they have been installed. Make sure you execute/run the code. We will explain what is happening below.
# Import necessary libraries
import os as os # for operations at the operating system level
import pandas as pd # For data manipulation
import numpy as np # For numerical computations
The command import pandas as pd imported all the functions that are associated with the pandas library. If we want to access functionality from that package, for instance the DataFrame function which will create a dataframe, we can, from now on, call this using the pd prefix, i.e. we would call it using pd.DataFrame().
The same has happened with the numpy llibrary which is used for many mathematical and statistical computations. The function which calculates the mean will be called, for instance, as np.mean().
Data Upload¶
Ensure that your working directory is set to the directory you are working from.
os.chdir("C:/Pycode") # Replace with your desired path
print("New Working Directory:", os.getcwd())
New Working Directory: C:\Pycode
As we are dealing with data in a csv file we will use the read.csv() function (from the pandas package) to load the data. We are lucky that this datafile has no missing data, meaning that it has no empty cells. Missing information all appear to be coded up as a special category in each of the variables. See the Data Dictionary to confirm that for the RoadType variable a 9 represents “Unknown”.
Now, let's load the datafile into a dataframe. Because the data file is a csv file we are going to use the df = pd.read.csv() function, as follows:
import pandas as pd
# Correct method to read the CSV file
file_name = "STATS19_GM_AccData.csv"
accdata = pd.read_csv(file_name) # Use read_csv, not read.csv
If you get an error message FileNotFoundError: [Errno 2] No such file or directory: 'STATS19_GM_AccData.csv' this means that the file is not in your working directory. Check that it is in the folder and that you spelled its name correctly.
The data now has been successfully loaded. It is stored in a panda data frame. You could think about it like a spreadsheet with rows and columns. It is time to inspect its structure using the following line:
# View basic information about the dataset
accdata.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 42624 entries, 0 to 42623 Data columns (total 27 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Accident Index 42624 non-null int64 1 Year 42624 non-null int64 2 Severity 42624 non-null int64 3 NumberVehicles 42624 non-null int64 4 NumberCasualties 42624 non-null int64 5 OutputDate 42624 non-null object 6 Day 42624 non-null int64 7 OutputTime 42624 non-null object 8 Easting 42624 non-null int64 9 Northing 42624 non-null int64 10 LocalAuthority 42624 non-null int64 11 Road1Class 42624 non-null int64 12 Road1Number 42624 non-null int64 13 CarriagewayType 42624 non-null int64 14 SpeedLimit 42624 non-null int64 15 JunctionDetail 42624 non-null int64 16 JunctionControl 42624 non-null int64 17 Road2Class 42624 non-null int64 18 Road2Number 42624 non-null int64 19 PedCrossingHumanControl 42624 non-null int64 20 PedCrossingPhysicalFacilities 42624 non-null int64 21 LightingCondition 42624 non-null int64 22 WeatherCondition 42624 non-null int64 23 RoadSurface 42624 non-null int64 24 SpecialConditions 42624 non-null int64 25 CarriagewayHazard 42624 non-null int64 26 PlaceReported 42624 non-null int64 dtypes: int64(25), object(2) memory usage: 8.8+ MB
The info() method is pandas concisely summarises the DataFrame. The output indicates 42,624 (rows), counting from 0 to 42,623). Each row represents one observation, such as a recorded road accident in Greater Manchester between 2010 and 2020. Each accident has variables which characterise the accident. In the table provided:
- the
Non-Null Countcolumn shows the number of non-missing (valid) entries for each column. This example shows that the Non-Null Count equals 42,624 for all columns listed, meaning there are no missing values in these variables! If any column had missing values, this count would be less than42624. - the
Dtypecolumn specifies each variable's data type. More specifically, we mostly haveint64, which represents a numerical value with integer values ( e.g.,Year,Severity). We can also indicateobjectusually representing text or categorical data.
These are some important variables to focus on:
Accident.Index: Unique identifier for each accident.Year: Year in which the accident occurred.Severity: Severity of the accident.NumberVehicles: Number of vehicles involved.NumberCasualties: Number of casualties involved.LightingCondition: Lighting conditions at the time of the accident.WeatherCondition: Weather conditions at the time of the accident.Road1Class: Classification of the main road (lower numbers = more major roads).RoadSurface: Road surface condition at the time of the accident.
We can also look at the first few rows of our dataset using the head() function. We can specify the number of rows to display e.g., accdata.head(5) for the first 5 rows, as follows:
print (accdata.head(5))
Accident Index Year Severity NumberVehicles NumberCasualties \ 0 102262412010 2010 3 2 1 1 102262562010 2010 3 2 1 2 102264322010 2010 3 2 1 3 107264182010 2010 3 3 1 4 114261842010 2010 3 1 1 OutputDate Day OutputTime Easting Northing ... Road2Class \ 0 01/01/2010 6 13:10 382347 390025 ... 3 1 01/01/2010 6 11:10 381892 390582 ... 7 2 01/01/2010 6 17:30 385840 403134 ... 7 3 01/01/2010 6 13:49 377762 403302 ... 1 4 01/01/2010 6 01:55 355982 404620 ... 0 Road2Number PedCrossingHumanControl PedCrossingPhysicalFacilities \ 0 5103 0 0 1 0 0 0 2 0 0 0 3 60 0 0 4 0 0 0 LightingCondition WeatherCondition RoadSurface SpecialConditions \ 0 1 1 4 0 1 1 1 4 0 2 4 1 2 0 3 3 9 1 0 4 7 9 1 0 CarriagewayHazard PlaceReported 0 0 1 1 0 1 2 0 2 3 0 2 4 0 2 [5 rows x 27 columns]
Data viewing¶
Above you already saw the use of the .head() method to see some data. But often you will want to have a look at the whole dataset (basically the spreadsheet). This is easily done in VS Code. Once you created any objects (we already created acc_data and file_name) you should see at the top of your notebook window a Jupyter Variables button. Click that and at the bottom of your screen you will see a list of the objects that have been created.
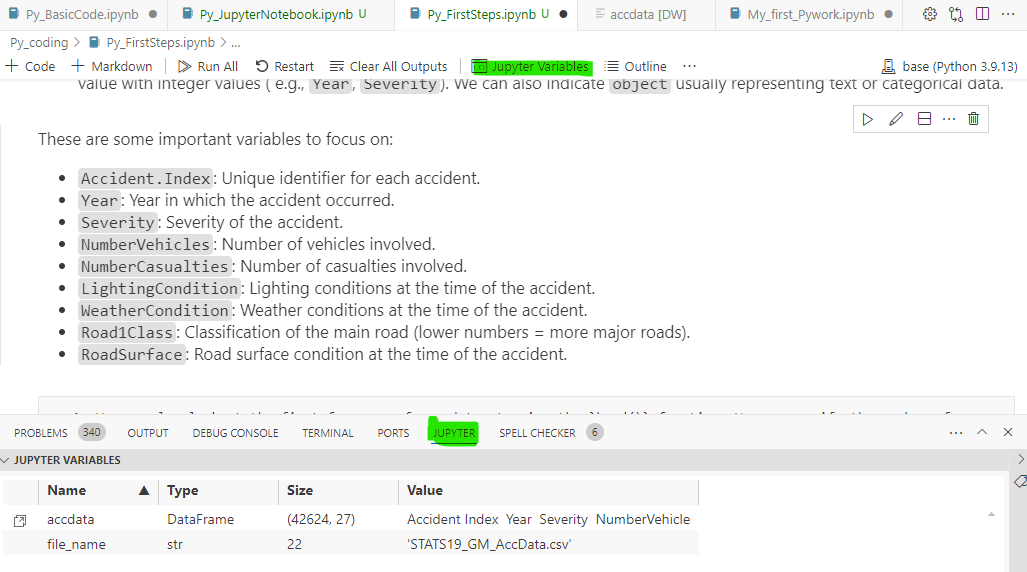
This view alone is already useful as it can be important to check whether objects have been created. If you double click on accdata you should either see the window below, or you will get a popup message telling you that you need to install a Data Viewer extension for VS Code. Say OK and you will get suggestions. We recommend the Data Wrangler extension. Install and then enable it. Once you have done that, double clicking on acc_data should create a new window in VS Code that displays the spreadsheet with a graphical data representation (histograms) at the top.
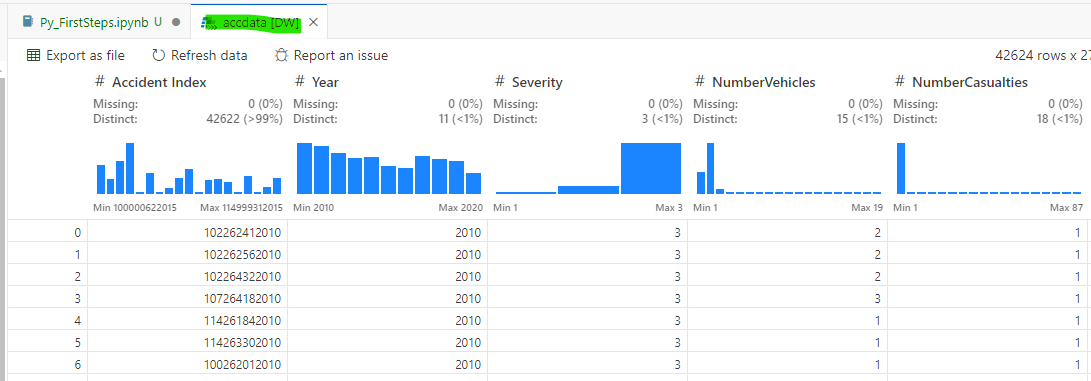
The ability of seeing a list of your objects and actually seeing the data is one of the most compelling reasons to use an IDE.
Saving and re-starting¶
Congratulations! You’ve written your first Python code in a Jupyter Notebook. Now, it’s time to take a well-deserved break. Save your notebook by typing CTRL + S (in Windows) or CMD + S (on a Mac) or by chosing the Save option in the File menu drop down box. After that, close VS Code, pretend it is the end of your working day. You don’t need to do this every time, but let’s do it now to demonstrate the value of scripts or notebooks. When you’re ready, reopen VS Code and navigate to your saved notebook file (the one with the .ipynb extension). Open it, and you’ll see that all your code is still there, just as you left it. However, the variables and data that were stored in memory will no longer be available.
Here’s where the magic of notebooks shines: click on Run All, or run your cells sequentially by pressing CTRL + Enter in each cell. All the commands in your notebook will re-execute, and your data (accdata, in this case) will be available again and ready for further analysis. So after pressing one button you are back at where you finished "yesterday". So you again started out from the original dataset.
Once you understand the usefulness of this workflow, the following very important principle will make sense.
An essential principle when working with data in Python is never to modify your original data file, which in this case is the
STATS19_GM_AccData.csvfile. This ensures the integrity of your data and allows you to start fresh whenever needed. Any changes made directly to the CSV file are permanent and cannot be undone. Therefore, keeping the original file untouched ensures that you always have a reliable reference point for your analysis.
Accessing Data¶
The accdata object in Python represents the dataset as a DataFrame, which is essentially a table-like structure. You can view the entire dataset or specific subsets of it using indexing and slicing techniques.
In Jupyter Notebook, to view the entire dataset you can look at it via the variable list (just as above) or you can run:
accdata
| Accident Index | Year | Severity | NumberVehicles | NumberCasualties | OutputDate | Day | OutputTime | Easting | Northing | ... | Road2Class | Road2Number | PedCrossingHumanControl | PedCrossingPhysicalFacilities | LightingCondition | WeatherCondition | RoadSurface | SpecialConditions | CarriagewayHazard | PlaceReported | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 102262412010 | 2010 | 3 | 2 | 1 | 01/01/2010 | 6 | 13:10 | 382347 | 390025 | ... | 3 | 5103 | 0 | 0 | 1 | 1 | 4 | 0 | 0 | 1 |
| 1 | 102262562010 | 2010 | 3 | 2 | 1 | 01/01/2010 | 6 | 11:10 | 381892 | 390582 | ... | 7 | 0 | 0 | 0 | 1 | 1 | 4 | 0 | 0 | 1 |
| 2 | 102264322010 | 2010 | 3 | 2 | 1 | 01/01/2010 | 6 | 17:30 | 385840 | 403134 | ... | 7 | 0 | 0 | 0 | 4 | 1 | 2 | 0 | 0 | 2 |
| 3 | 107264182010 | 2010 | 3 | 3 | 1 | 01/01/2010 | 6 | 13:49 | 377762 | 403302 | ... | 1 | 60 | 0 | 0 | 3 | 9 | 1 | 0 | 0 | 2 |
| 4 | 114261842010 | 2010 | 3 | 1 | 1 | 01/01/2010 | 6 | 01:55 | 355982 | 404620 | ... | 0 | 0 | 0 | 0 | 7 | 9 | 1 | 0 | 0 | 2 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 42619 | 100792182020 | 2020 | 3 | 2 | 1 | 31/12/2020 | 5 | 06:40 | 369900 | 406661 | ... | 0 | 0 | 0 | 0 | 4 | 3 | 3 | 0 | 0 | 2 |
| 42620 | 102787772020 | 2020 | 3 | 2 | 1 | 31/12/2020 | 5 | 06:30 | 384711 | 392657 | ... | 0 | 0 | 0 | 0 | 7 | 3 | 3 | 0 | 0 | 2 |
| 42621 | 102790472020 | 2020 | 3 | 2 | 2 | 31/12/2020 | 5 | 20:10 | 387961 | 397434 | ... | 7 | 0 | 0 | 5 | 4 | 1 | 4 | 0 | 0 | 1 |
| 42622 | 106790322020 | 2020 | 3 | 2 | 2 | 31/12/2020 | 5 | 15:00 | 390392 | 412917 | ... | 4 | 640 | 0 | 0 | 1 | 1 | 2 | 0 | 0 | 2 |
| 42623 | 110787712020 | 2020 | 2 | 1 | 1 | 31/12/2020 | 5 | 11:56 | 394153 | 399197 | ... | 7 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 1 |
42624 rows × 27 columns
Let's say we want to explore various ways to subset the accdata DataFrame. To subset in coding lingo means to access particular parts of the dataframe. To select specific rows we can run the following code:
# Select the first row
print(accdata.iloc[0]) # Note: Python indexing starts at 0, not 1
# Select rows 7 to 10 (inclusive of start, exclusive of end)
print(accdata.iloc[7:11])
Accident Index 102262412010
Year 2010
Severity 3
NumberVehicles 2
NumberCasualties 1
OutputDate 01/01/2010
Day 6
OutputTime 13:10
Easting 382347
Northing 390025
LocalAuthority 102
Road1Class 5
Road1Number 5166
CarriagewayType 3
SpeedLimit 50
JunctionDetail 6
JunctionControl 2
Road2Class 3
Road2Number 5103
PedCrossingHumanControl 0
PedCrossingPhysicalFacilities 0
LightingCondition 1
WeatherCondition 1
RoadSurface 4
SpecialConditions 0
CarriagewayHazard 0
PlaceReported 1
Name: 0, dtype: object
Accident Index Year Severity NumberVehicles NumberCasualties \
7 101262292010 2010 3 2 1
8 102256832010 2010 3 2 1
9 102256922010 2010 3 1 1
10 102262112010 2010 2 2 2
OutputDate Day OutputTime Easting Northing ... Road2Class \
7 02/01/2010 7 13:00 381775 410735 ... 7
8 02/01/2010 7 18:25 383868 394065 ... 4
9 02/01/2010 7 18:35 384681 395127 ... 7
10 02/01/2010 7 06:50 384660 397391 ... 0
Road2Number PedCrossingHumanControl PedCrossingPhysicalFacilities \
7 0 0 0
8 6010 0 5
9 0 0 0
10 0 0 0
LightingCondition WeatherCondition RoadSurface SpecialConditions \
7 1 3 3 0
8 4 3 2 0
9 4 8 4 0
10 4 1 4 0
CarriagewayHazard PlaceReported
7 0 2
8 0 1
9 0 1
10 0 1
[4 rows x 27 columns]
The iloc stands for "integer location" and the iloc[0] accesses the first row of the DatFrame using positional indexing.
Note that in Python, indexing starts at 0, unlike R, which starts at 1.
If you want to examine a subset of rows without displaying the entire dataset, we can run the iloc[3:6] method. As you can see from the output above, this particular function selects rows 4 to 6.
Note that Python slicing is exclusive of the end index, so it stops at row 6 but doesn’t include it!
We can follow the same proccedure for selecting specific columns instead of rows by using the iloc[:, 1]and for selecting a range of columns iloc[:, 3:6].
Let's say now that we want to select particular variables (columns in a spreadsheet). We can do this by running this line of code:
accdata['SpeedLimit']
0 50
1 30
2 30
3 30
4 30
..
42619 30
42620 30
42621 30
42622 30
42623 30
Name: SpeedLimit, Length: 42624, dtype: int64
accdata['SpeedLimit'] acceesses the SpeedLimit column by it's name. This results in a pandas Series which is a one-dimensional array-like structure. If you wish to access two variables you could do that as follows:
sel_col = ['SpeedLimit', 'Road1Class']
accdata[sel_col]
| SpeedLimit | Road1Class | |
|---|---|---|
| 0 | 50 | 5 |
| 1 | 30 | 7 |
| 2 | 30 | 4 |
| 3 | 30 | 4 |
| 4 | 30 | 4 |
| ... | ... | ... |
| 42619 | 30 | 6 |
| 42620 | 30 | 5 |
| 42621 | 30 | 4 |
| 42622 | 30 | 7 |
| 42623 | 30 | 7 |
42624 rows × 2 columns
In sel_col we have created a list of items, here the two variable names, which was then used in accdata[sel_col].
Lists are an incredibly important object type in Python. YOu could create a list containing mixed data types? We can do this as follows:
silly_list = ["Countries in the EU", 28 - 1, ":-("]
Creating a list of different data types could be quite useful when creating dynamic datasets or labels. In this particular example, we have created a list that combines two strings ( e.g., "Countries in the EU" and ":-(" ) and an integer resulting from the subtraction operation (e.g., 28-1).
Investigate Data 1¶
Let’s explore how the severity of an accident is coded in the dataset. In Python, this can be done using the unique() method from pandas and the value_counts() method to inspect the distribution of values.
# Find unique values in the 'Severity' column
unique_severity = accdata['Severity'].unique()
print("Unique values in 'Severity':", unique_severity)
Unique values in 'Severity': [3 2 1]
The output indicates that the Severity variable takes three distinct values: 1, 2, and 3. But what do the values 1, 2 or 3 represent? You could go to the data dictionary and check the coding, although on this occasion that turns out less than conclusive. Does a 1 in the Severity variable represent a fatal accident or a slight one? To determine this, we can analyse the data directly. It’s reasonable to assume that slight accidents occur more frequently than fatal ones. While the data dictionary may provide this information, we can infer the meaning of each category by looking at the distribution of accidents across these values. Categories with more observations are likely less severe (e.g., slight accidents), while those with fewer observations are likely more severe.
The easiest way to look at this is to use the value_counts() method on the Severity variable.
# Count the number of accidents in each severity category
severity_counts = accdata['Severity'].value_counts()
print("Counts of each Severity level:\n", severity_counts)
Counts of each Severity level: 3 35523 2 6519 1 582 Name: Severity, dtype: int64
This function counts the occurrences of each unique value in the column and sorts them in descending order. So, from the output provided here, we can conclude that category 1 represents the most severe accident category and category 3 represents the least severe (e.g., slight accidents) one.
Data Formats¶
From the dataset overview (accdata.info()), we can see:
- Most variables, including
Severity,WeatherCondition, andRoadSurface, are stored asint64, meaning they are treated as numeric values. - Text-based variables like
OutputDateandOutputTimeare stored as object, which is how Python handles strings.
While these numeric variables (Severity, WeatherCondition, etc.) are numbers, they actually represent categories. For instance, Severity: 1 = Fatal, 2 = Serious, 3 = Slight. It’s more meaningful to treat these variables as categorical instead of numeric. To do this in Python, we use pandas' astype('category') to convert a numeric column to a categorical column. Additionally, we can assign readable labels using cat.rename_categories method.
Hence we will create a new variables, Severityf which contains the same info, but just in a way easier to understand.
# Convert 'Severity' to a categorical variable
accdata['Severityf'] = accdata['Severity'].astype('category')
accdata['Severityf'] = accdata['Severityf'].cat.rename_categories({1: "Fatal", 2: "Serious", 3: "Slight"})
# Check the result
print(accdata['Severityf'].value_counts())
Slight 35523 Serious 6519 Fatal 582 Name: Severityf, dtype: int64
There are a number of important elements in these lines:
- The
accdata['Severityf']accesses the original Severity column in the DataFrame, and then the.astype(severity_categories)converts the numericSeveritycolumn into a categorical variable using the predefined categories (severity_categories). This ensures thatSeverityis treated as an ordinal variable with the defined categories (1 = Fatal, 2 = Serious, 3 = Slight). - The
cat.rename_categories()function renames the categories from numeric (1, 2, 3) to meaningful labels (Fatal, Serious, Slight). - The
values_count()displays the count of each category to verify the transformation.
Of course you should look at this and say "How on earth should I have known how to do that?".
How to find the code?¶
Use the community¶
The point is that you are not expected to know all details. When we wrote this we also had to check this. Here are two techniques of how to find solutions to your coding questions.
Search the internet¶
YOu could go to your favourite internet search engine and enter search terms as the following: "python pandas rename category". Everyone will get a slightly different list of links, but you are likely to quickly find either links to stackoverflow.com (which is a good place to go) or to documentation for python functions. The stackoverflow link we got gave, amongst others, the following example.
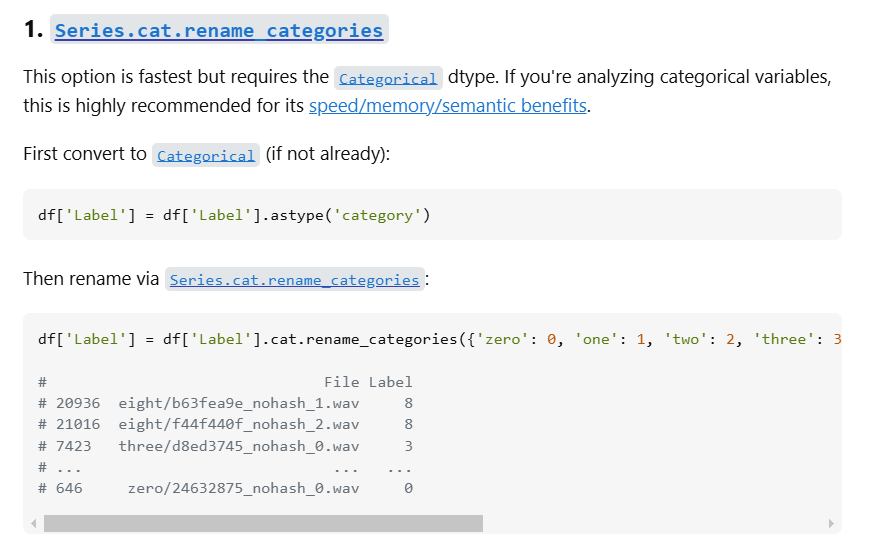
If you compare the code here with the one we used above you can see that we merely adjusted the code we found here. Adapting such a solution to your problem is a very common activity as a coder.
Ask a GenAI engine¶
GenAI engines such as ChatGPT or Claude can help you out with coding problems. You need to start with a clear problem setup in order to get something useful.
This image only shows the first method proposed by ChatGPT and you can see it is different. However, it made multiple proposals and the method we used above also appears a little further down.
¶
Now create two new variables WeatherConditionf and RoadSurfacef which achieve the same for the WeatherCondition and RoadSurface variables. Converting WeatherCondition to a categorical variable involves you checking the Data Dictionary for the right ordering. Then you should run the following code:
# Convert 'WeatherCondition' to a categorical variable
accdata['WeatherConditionf'] = accdata['WeatherCondition'].astype('category')
accdata['WeatherConditionf'] = accdata['WeatherConditionf'].cat.rename_categories({
1: 'Fine, no winds',
2: 'Raining, no winds',
3: 'Snow, no winds',
4: 'Fine, with winds',
5: 'Raining, with winds',
6: 'Snow, with winds',
7: 'Fog or mist',
8: 'Other',
9: 'Unknown'
})
# Check the result
print(accdata['WeatherConditionf'].value_counts())
Fine, no winds 32535 Raining, no winds 5997 Unknown 1717 Other 859 Raining, with winds 705 Fine, with winds 404 Snow, no winds 246 Fog or mist 96 Snow, with winds 65 Name: WeatherConditionf, dtype: int64
Again, here the .astype('category') method creates the categorical variable. The cat.rename_categories() method maps each numeric category to its descriptive label (e.g., 1 -> 'Fine, no winds'). Finally, the value_counts() function verifies the transfomation and ensures the correct mapping.
Converting RoadSurface to a categorical variable involves you again checking the Data Dictionary for the correct ordering. Then you should run the following code:
# Convert 'RoadSurface' to a categorical variable
accdata['RoadSurfacef'] = accdata['RoadSurface'].astype('category')
# Rename categories with meaningful labels
accdata['RoadSurfacef'] = accdata['RoadSurfacef'].cat.rename_categories({
1: 'Dry',
2: 'Wet/Damp',
3: 'Snow',
4: 'Frost/Ice',
5: 'Flood',
6: 'Oil or Diesel',
7: 'Mud'
})
# Check the result
print(accdata['RoadSurfacef'].value_counts())
Dry 29175 Wet/Damp 12662 Frost/Ice 530 Snow 226 Flood 31 Name: RoadSurfacef, dtype: int64
And let’s also check the number of accidents in the different weather conditions and for different road surface conditions:
# Check the number of accidents in specific categories
print("Accidents in 'Snow, no winds':", (accdata['WeatherConditionf'] == 'Snow, no winds').sum())
print("Accidents on flooded roads:", (accdata['RoadSurfacef'] == 'Flood').sum())
Accidents in 'Snow, no winds': 246 Accidents on flooded roads: 31
The (accdata['WeatherConditionf'] == 'Snow, no winds').sum()) filters for accidents in the WeatherConditionf column labelled 'Snow, no Winds' and counts them, whereas the (accdata['RoadSurfacef'] == 'Flood').sum()) counts the accidents labelled as 'Flood' in the RoadSurfacef column. From the output, we can conclude that there were 246 accidents in “Snow, no winds” conditions and 31 accidents on flooded roads.
Investigate Data 2¶
Now we wish to look at the relation between two variables, sat the weather condition at the time of an accident and the accident's severity. We previously used the unique() function from pandas and the value_counts() method to inspect the distribution of values. However, to analyse the joint distribution of two categorical variables and compute proportions, using Python, we are going to be focusing on some different functions. Let's create a frequency table. In this case we can use the pd.crosstab() function as follows:
# Create a frequency table for WeatherConditionf and Severityf
frequency_table = pd.crosstab(accdata['WeatherConditionf'], accdata['Severityf'])
print(frequency_table)
Severityf Fatal Serious Slight WeatherConditionf Fine, no winds 458 5232 26845 Raining, no winds 67 786 5144 Snow, no winds 3 19 224 Fine, with winds 9 56 339 Raining, with winds 14 109 582 Snow, with winds 1 12 52 Fog or mist 4 14 78 Other 6 63 790 Unknown 20 228 1469
The pd.crosstab() function creates a contingency table showing the frequency of observations for each combination of WeatherConditionf and Severityf. This output shows the raw counts of accidents by weather condition and severity. For instance, there were 9 fatal accidents in fine weather with winds. It is often more instructive to look at proportions rather than numbers. That is easily achieved by adding the normalize = True option to the function.
# Compute overall proportions
proportion_table = pd.crosstab(accdata['WeatherConditionf'], accdata['Severityf'], normalize=True)
print(proportion_table)
Severityf Fatal Serious Slight WeatherConditionf Fine, no winds 0.010745 0.122748 0.629809 Raining, no winds 0.001572 0.018440 0.120683 Snow, no winds 0.000070 0.000446 0.005255 Fine, with winds 0.000211 0.001314 0.007953 Raining, with winds 0.000328 0.002557 0.013654 Snow, with winds 0.000023 0.000282 0.001220 Fog or mist 0.000094 0.000328 0.001830 Other 0.000141 0.001478 0.018534 Unknown 0.000469 0.005349 0.034464
The above fucntion with normalize=True calculates the proportion of each cell relative to the total number of observations. Here, each value represents the proportion of accidents for a specific combination of weather and severity relative to the total number of accidents. More specifically, you can see that 63% of all accidents are slight accidents in fine weather with no winds. If you add up all these proportions, you will get 1!
This is still only moderatly insightful. Let's try to create a connditional proportion table. More specifically, let's compute proportions conditional on the Severityf, as follows:
# Compute proportions conditional on Severity (columns)
proportion_table_col = pd.crosstab(accdata['WeatherConditionf'], accdata['Severityf'], normalize='columns')
print(proportion_table_col)
Severityf Fatal Serious Slight WeatherConditionf Fine, no winds 0.786942 0.802577 0.755708 Raining, no winds 0.115120 0.120571 0.144808 Snow, no winds 0.005155 0.002915 0.006306 Fine, with winds 0.015464 0.008590 0.009543 Raining, with winds 0.024055 0.016720 0.016384 Snow, with winds 0.001718 0.001841 0.001464 Fog or mist 0.006873 0.002148 0.002196 Other 0.010309 0.009664 0.022239 Unknown 0.034364 0.034975 0.041353
You can now see that we are using the same function as before pd.crosstab() but now we assign normalize='columns'! This divides each cell by the total for its column, showing the proportion of each weather condition within a severity category. We can conclude that when conditioning on severity, we see that 75-80% of accidents in each severity level occur in fine weather with no winds!
Previously the condition assigned was on columns (Severityf), how about if we compute porportions conditional on WeatherConditionf (rows)?
# Compute proportions conditional on WeatherCondition (rows)
proportion_table_row = pd.crosstab(accdata['WeatherConditionf'], accdata['Severityf'], normalize='index')
print(proportion_table_row)
Severityf Fatal Serious Slight WeatherConditionf Fine, no winds 0.014077 0.160811 0.825111 Raining, no winds 0.011172 0.131066 0.857762 Snow, no winds 0.012195 0.077236 0.910569 Fine, with winds 0.022277 0.138614 0.839109 Raining, with winds 0.019858 0.154610 0.825532 Snow, with winds 0.015385 0.184615 0.800000 Fog or mist 0.041667 0.145833 0.812500 Other 0.006985 0.073341 0.919674 Unknown 0.011648 0.132790 0.855562
We can now see that we have assigned normalize='index'. This divides each cell by the total for its row, showing the proportion of accidents by severity within a given weather condition. Here, we can conclude that when conditioning on the weather (normalize='index'), most weather conditions show a majority of slight accidents (e.g., 85% of accidents in the rain with no winds are slight).
If you are looking at categorical variables only then looking at tables of frequencies or proportions, as above, is the right way to go. However, when you are interested in outcomes of variables which are truly numerical, meaning that the actual number has a meaning (like the number of vehicles and casualties involved), then looking at numbers of frequencies may not be the best way to look at the variables. It may make sense to look at some summary statistics like, means, medians and standard deviations (e.g., using the describe() function).
A Glimpse Through Visualization¶
Python's data visualization ecosystem is as vast as it is diverse, offering tools to meet every need—from straightforward plots to highly customized, interactive masterpieces. At its core lies the powerhouse library, matplotlib, the bedrock upon which many other visualization tools are built. Complementing it is seaborn, a high-level library that simplifies the creation of aesthetically pleasing and informative statistical plots, making it a go-to for exploratory data analysis.
But don't worry, we're not here to bury you in the details. Sit back, relax, and enjoy the show as we unveil what some of Python's visualization tools can do.
The way in which graphs are built using these packages can be quite complex and it is most likely new to you. If you come from programming in R you will be happy to hear that there is now a Python equivalent to the ggplot package in R. The package is called lets_plot in Python. It basically allows you to use the ggplot way of building graphs. An introduction to that package is available from this walkthrough.
The first step is to import the required libraries:
import matplotlib.pyplot as plt
import seaborn as sns
Let's now create a simple scatter plot:
# Basic scatter plot to visualize accident locations
plt.figure(figsize=(10, 8)) # Set the figure size
plt.scatter(accdata['Easting'], accdata['Northing'], s=0.5, alpha=0.6)
plt.title("Locations of Vehicle Accidents in Greater Manchester")
plt.xlabel("Easting")
plt.ylabel("Northing")
plt.show()

There are a number of important elements in these lines:
hplt.scatter()creates a scatter plot usingEasting(x-axis) andNorthing(y-axis)e- The
s=0.5sets the size of each point. - The
alpha=0.6adds some transparency to reduce overplotting - ta.
plt.figure(figsize=(10, 8))isets the size of the plot for better readability.t ics. At the same time we can also specify the customizing Legends. More specifically, the bbox_to_anchor and loc move the legend outside the plot for clarity.
This plot gives a basic visualization of accident locations. The points form a rough outline of the road network in Greater Manchester. The next image adds a few flourishes to the picture by adding colours based on road class:
# Scatter plot with colors for Road1Class
plt.figure(figsize=(12, 10)) # Adjust the figure size
sns.scatterplot(
x='Easting',
y='Northing',
hue='Road1Class', # Color points by Road1Class
data=accdata,
palette='viridis', # Color palette
s=10, # Point size
alpha=0.7 # Transparency
)
plt.title("Locations of Vehicle Accidents in Greater Manchester by Road Class")
plt.xlabel("Easting")
plt.ylabel("Northing")
plt.legend(title="Road Class", bbox_to_anchor=(1.05, 1), loc='upper left') # Move legend outside
plt.show()

There are a number of important elements in these lines:
- The
sns.scatterplot()creates a scatter plot wherex='Easting'andy='Northing'are the coordinates. - The
hue='Road1Class'function colours the points based onRoad1Class. - The
data=accdatafunction specifies the DataFrame as the source of data. - The
palette='viridis'uses a colour palette for better aesthetics.
At the same time we can also specify the customizing Legends. More specifically, the bbox_to_anchor and loc move the legend outside the plot for clarity.
This was only meant to get you a little excited about creating graphical representations of your work. Especially if you have previously worked with ggplot in R you may find this walkthrough to be a great introduction into creating graphs in Python.
Summary¶
Before wrapping up your session in Jupyter Notebook, make sure to save your notebook file. That means that tomorrow you can just come back open the script file and continue to work. But before you do that recall what you learned here. You learned
- about the architecture of Jupyter notebooks
- how to import data into Python
- how to inspect objects that were created during your work
- how to create categorical variables and rename them
- how to create contingency tables
- that Python has powerful graphing tools
This walkthrough is part of the ECLR page.